NLP(四十六)对抗训练的一次尝试
初次听说对抗训练是在一次实体识别比赛的赛后分享中,当时的一些概念,比如Focal Loss、对抗训练、模型融合、数据增强等都让我感到新奇,之后笔者自己也做了很多这方面的尝试。本文将分享笔者对于对抗训练(FGM)的一次尝试。
什么是对抗训练?
提到“对抗”,相信大多数人的第一反应都是CV中的对抗生成网络
(GAN),殊不知,其实对抗也可以作为一种防御机制,并且经过简单的修改,便能用在NLP任务上,提高模型的泛化能力。GAN之父Ian
Goodfellow在15年的ICLR论文《Explaining and Harnessing Adversarial
Examples》中第一次提出了对抗训练这个概念,简而言之,就是在原始输入样本x上加一个扰动radv,得到对抗样本后,用其进行训练。这在CV领域比较好理解,部分图片本身就是自带噪声的,比如手抖、光线不佳等,这就是天然的对抗样本,它们在模型训练的时候就是负样本,这些样本的加入能提升模型的鲁棒性。比如下面的经典例子:
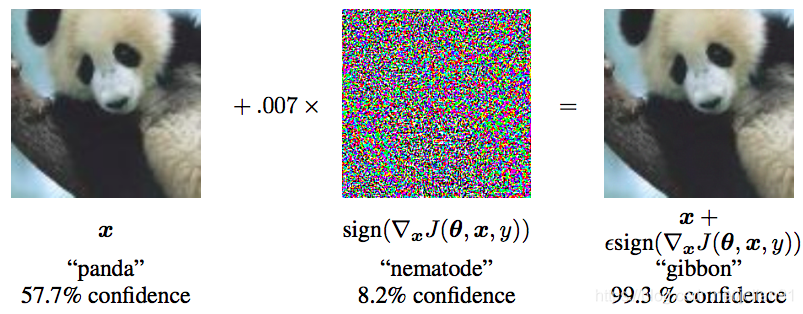
从上面的例子中,我们可以看到一张置信度为55.7%的panda图片在加入了很小的随机扰动后,模型竟然识别为了gibbon。
对抗训练的一般原理可以用下面的最大最小化公式来体现:
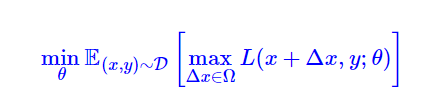
其中D代表训练集,x代表输入,y代表标签,θ是模型参数,L(x,y;θ)是单个样本的loss,Δx是对抗扰动,Ω是扰动空间。Ω是扰动空间,Δx是对抗扰动,一般扰动空间都比较小,避免对原来样本的破坏。在训练集合D,选择合适的对抗扰动来使得当个样本的loss达到最大,同时,外层(E(x,y))就是对神经网络的模型参数θ进行优化,使其最小化。这颇有一点攻与守的味道,有了随机扰动的加入,样本的loss要尽可能大,而训练的模型loss要尽可能小,从而使得模型有了更强的鲁棒性,避免样本的小扰动就造成模型推理的结果偏差。
FGM
FGM(Fast Gradient Method)是对抗学习的一种实现方式,可以与FGSM(Fast Gradient Sign Method)一起谈论。对于随机扰动Δx,FGM与FGSM的实现公式如下:
\[FGSM: \Delta{x}=\epsilon\cdot Sign(g) \\ FGM: \Delta{x}=\epsilon\cdot (g/||g||_{2}) \\ 其中Sign为数学函数,||g||_{2}为g的L_{2}范数, g=\nabla_{x}L(x;y;\theta).\]
从上面的公式上可以看出,其增大样本loss的办法是使得样本x在梯度方向变大。
CV领域中,上面的FGM公式比较容易实现,因为图片的向量表示我们可以认为是连续的实数,而在NLP中,一般字或词的表示为One-hot向量,不好直接进行样本扰动。一种简单的想法是在word Embedding向量的时候进行扰动。Embedding层的输出是直接取自于Embedding参数矩阵的,因此我们可以直接对Embedding参数矩阵进行扰动。这样得到的对抗样本的多样性会少一些(因为不同样本的同一个token共用了相同的扰动),但仍然能起到正则化的作用,而且这样实现起来容易得多。
我们不必自己动手去实现上述的FGM,苏建林在bert4keras工具中已经实现了FGM的脚本,可以参考:https://github.com/bojone/keras_adversarial_training,这是Keras框架下的实现。而瓦特兰蒂斯在博客【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现中给出了Torch框架下的FGM实现。两者使用起来都非常方便。
下面将介绍笔者使用FGM在keras-bert模块中的实验。
实验结果
笔者使用keras-bert模块实现了命名实体识别、文本多分类、文本多标签分类任务,如下:
NLP(三十六)使用keras-bert实现文本多标签分类任务
我们将对比在同样的模型参数下,相同数据集在使用FGM前后的模型评估指标的对比:
人民日报实体识别任务(评估指标为micro avg f1-score)
| - | 训练1 | 训练2 | 训练3 | avg |
|---|---|---|---|---|
| 使用FGM前 | 0.9276 | 0.9217 | 0.9252 | 0.9248 |
| 使用FGM后 | 0.9287 | 0.9273 | 0.9294 | 0.9285 |
- 时间识别任务(评估指标为micro avg f1-score)
| - | 训练1 | 训练2 | 训练3 | avg |
|---|---|---|---|---|
| 使用FGM前 | 0.8926 | 0.8934 | 0.8820 | 0.8893 |
| 使用FGM后 | 0.9037 | 0.8798 | 0.8911 | 0.8915 |
- 搜狗数据集文本多分类模型(评估指标为micro avg f1-score)
| - | 训练1 | 训练2 | 训练3 | avg |
|---|---|---|---|---|
| 使用FGM前 | 0.9778 | 0.9697 | 0.9657 | 0.9711 |
| 使用FGM后 | 0.9778 | 0.9838 | 0.9838 | 0.9818 |
- THUCNews数据集文本多分类模型(评估指标为micro avg f1-score)
| - | 训练1 | 训练2 | 训练3 | avg |
|---|---|---|---|---|
| 使用FGM前 | 0.9524 | 0.9621 | 0.9685 | 0.961 |
| 使用FGM后 | 0.9689 | 0.9723 | 0.9712 | 0.9708 |
- 事件类型文本多标签模型(评估指标为accuracy)
| - | 训练1 | 训练2 | 训练3 | avg |
|---|---|---|---|---|
| 使用FGM前 | 0.8985 | - | - | - |
| 使用FGM后 | 0.9159 | 0.9192 | 0.9186 | 0.9179 |
以上对比结果已经上传至Github,网址如下:
命名实体识别:https://github.com/percent4/keras_bert_sequence_labeling
文本多分类:https://github.com/percent4/keras_bert_text_classification
文本多标签文本:https://github.com/percent4/keras_bert_multi_label_cls
总结经验为:
- 对抗训练FGM在很多NLP任务中可以有效提升模型效果,但代价是训练时间变长,一般是原来的1.5~2倍。
- FGM一般在小样本数据集上的提升效果较为明显。
- FGM并不一定总是能提升模型效果,比如笔者使用R-BERT在人物关系分类数据集上,使用FGM的效果反而变差了。
总结
本文主要介绍了对抗训练的概念,以及FGM实现方式和它在不同NLP任务上的模型效果对比。
最近笔者在使用keras bert实现多项选择阅读理解任务,但keras bert比较吃显存,而且模型结构写起来比较麻烦且效果有点儿出入。而用PyTorch实现的transformers模块,使用方便而且效果也好,不得不说,Torch真香!这并不是说Keras不行,而是Torch确实使用起来很方便。这只是我现在的体会,不必过于较真。
感谢大家阅读~
2021年4月14日深夜于上海浦东,此日上海天色阴沉~
参考文献
- 对抗训练浅谈:意义、方法和思考(附Keras实现): https://spaces.ac.cn/archives/7234
- 【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现: https://fyubang.com/2019/10/15/adversarial-train/
- 论文阅读:对抗训练(adversarial training): https://zhuanlan.zhihu.com/p/104040055

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
