OCR入门(一)OCR模型训练实战:破解汉字验证码
本文将会介绍如何使用CnOCR工具包来训练自己的OCR模型,实现汉字验证码的破解。本文作为OCR入门的第一篇文章,具有很强的实战性和一定的趣味性,适合新手入门。
在前几年的文章中,笔记曾经介绍了很多验证码破解方面的工作,在此汇总如下:
笔者一直都对破解验证码有着浓厚的兴趣,这几年因为从事NLP工作的缘故,没能保持对验证码的研究。我想还是要继续这方面的研究的。
之前的文章,破解的验证码大多是数字或者英文字母类型的,用的模型也是简单的CNN模型,偶尔也有滑动验证码,这种可用物体检测模型即可。之前的验证码通常只需要少量的样本(1K左右)就能取得不错的效果,但如果是汉字验证码,由于汉字数量的庞大,加上汉字的组合,因此标注少量样本或者简单的CNN模型,一般很难取得较好的识别效果。笔者之前关于验证码的研究就卡在此处。
最近有了一些突破,就是借助标注平台和CnOCR工具包进行破解,对汉字验证码识别有很好的效果。
下面笔者将会介绍如何破解汉字验证码破解方面。本项目已经开源,可以访问:https://github.com/percent4/Chinese_Captcha_Recognizition 。
数据集
我们将要破解的汉字验证码如下:

一般验证码图片尺寸都不大,本次使用的图片尺寸为75 * 20。每张验证码有三个汉字组成,且中间的汉字往往会与两边汉字有部分重叠。
一般,账号注册网站都会使用验证码,因此,可通过接口调用来批量生成验证码图片。
图片生成过程并不困难,而且接口一般也都容易破解,难的是对图片的标注。
笔者在这个项目中,使用Label Studio平台和自己写的标注平台对生成的验证码进行人工标注。
- 对于
Label Studio平台,笔者导入并标注了2500张图片 - 对于自己写的标注平台,笔者使用
damo/ofa_ocr-recognition_general_base_zh模型进行预标注,然后对这些标注结果进行人工审查,共标注6533个样本。经统计,预标注的准确个数为2699,准确率为41.31%。
因此,一共有9033个标注样本。对于标注样本,我们做一些简单的统计:
- 共有487个汉字
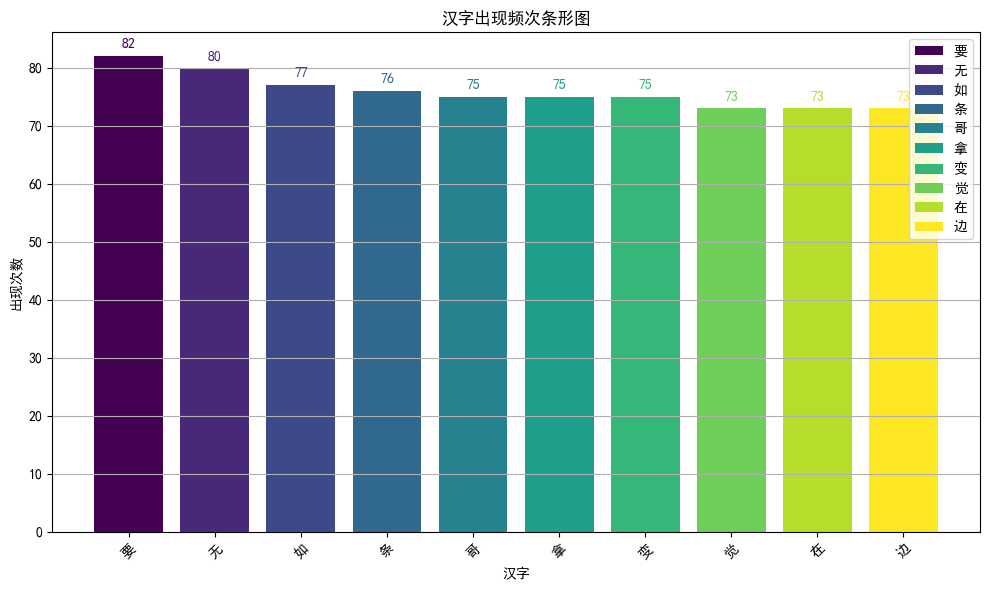
- 出现频率最高的汉字为要,共出现82次;出现频率最低的汉字为你,共出现35次。
- 按出现频次进行排序,前10位的汉字如下图所示:
模型训练
接下来,我们使用CnOCR工具包对上述标注数据集进行模型训练。
CnOCR是Python 3下的文字识别(Optical Character Recognition,简称OCR)工具包,支持简体中文、繁体中文(部分模型)、英文和数字的常见字符识别,支持竖排文字的识别。自带了20+个训练好的识别模型,适用于不同应用场景,安装后即可直接使用。同时,CnOCR也提供简单的训练命令供使用者训练自己的模型。
我们选择的基座识别模型(rec_model)为densenet_lite_136-gru。
同时,将标注数据集按训练集与验证集8:2划分,其中训练集样本7162个,验证集样本1827个。
按照CnOCR工具包模型训练的要求,我们需要给出如下训练文件:
- 图片目录: corpus
- 标签文件(词汇表): label.txt,每个汉字单独一行,代表一个标签
- 标注数据: 训练集train.tsv和验证集dev.tsv,每行中包含图片名字和文字内容,文字用空格隔开。训练集train.tsv中的前5行如下:
1 | |
对照CnOCR的模型训练官方文档,在配置文件(docs/examples/train_config.json)中,我们配置好图片和标注数据路径,将训练轮数(epoch)设置为100,利用下面的命令进行自定义OCR模型训练:
1 | |
耐心等待模型训练完毕,如需GPU加速,可使用train_config_gpu.json配置文件。
模型验证
对于训练好的模型文件,我们将其导出为onnx格式:
1 | |
对于导出后的文件,我们在验证集dev.tsv上进行模型效果评估,命令如下:
1 | |
这里我们需要使用刚导出为onnx格式的模型,配置好该模型的词汇表文件label.txt,以及验证集图片。
仅使用CPU,整个模型评估的速度也是相当快的。经评估,验证集共1827个样本,识别正确率高达为91.24%,比使用damo/ofa_ocr-recognition_general_base_zh模型预标注的41.31%准确率高出一大截,取得了很好的识别效果。
如果我们需要对新的验证码图片进行预测,有以下两种方法:
- 命令行
1 | |
- Python代码
1 | |
总结
本文主要介绍了如何使用CnOCR工具包,对自己标注的汉字验证码进行模型训练,并取得了不错的识别效果。
本文介绍的项目已开源至Github,网址为:https://github.com/percent4/Chinese_Captcha_Recognizition 。
下一篇文章笔者将会破解的汉字验证码包含4个汉字,且形式更加复杂:

后续笔者将会对 验证码破解工作
进行整理,形成体系化工作,也会将整理工作发表在自己的知识星球中,欢迎大家关注~
参考文献
- CnOCR官网:https://cnocr.readthedocs.io/zh-cn/stable/
- CnOCR脚本工具:https://cnocr.readthedocs.io/zh-cn/stable/command/
- 汉字验证码破解项目:https://github.com/percent4/Chinese_Captcha_Recognizition