# -*- coding: utf-8 -*- # @Time : 2023/3/16 10:32 # @Author : Jclian91 # @File : preprocessing.py # @Place : Minghang, Shanghai from random import shuffle import pandas as pd from collections import Counter, defaultdict
from params import TRAIN_FILE_PATH, NUM_WORDS from pickle_file_operaor import PickleFileOperator
classFilePreprossing(object): def__init__(self, n): # 保留前n个字 self.__n = n
def_read_train_file(self): train_pd = pd.read_csv(TRAIN_FILE_PATH) label_list = train_pd['label'].unique().tolist() # 统计文字频数 character_dict = defaultdict(int) for content in train_pd['content']: for key, value in Counter(content).items(): character_dict[key] += value # 不排序 sort_char_list = [(k, v) for k, v in character_dict.items()] shuffle(sort_char_list) print(f'total {len(character_dict)} characters.') print('top 10 chars: ', sort_char_list[:10]) # 保留前n个文字 top_n_chars = [_[0] for _ in sort_char_list[:self.__n]]
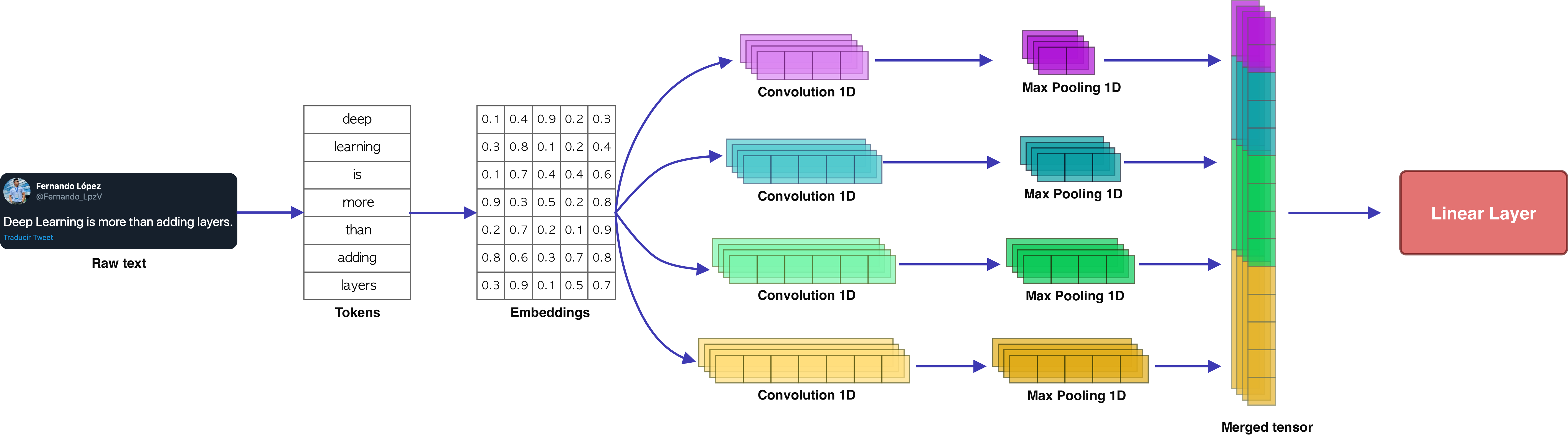
# The output of each convolutional layer is concatenated into a unique vector union = torch.cat((x1, x2, x3, x4), 2) union = union.reshape(union.size(0), -1)
# The "flattened" vector is passed through a fully connected layer out = self.fc(union) # Dropout is applied out = self.dropout(out) # Activation function is applied # out = nn.Softmax(dim=1)(out)
# -*- coding: utf-8 -*- import torch from torch.optim import RMSprop, Adam from torch.nn import CrossEntropyLoss, Softmax import torch.nn.functional as F from torch.utils.data import DataLoader from numpy import vstack, argmax from sklearn.metrics import accuracy_score
from model import TextClassifier from text_featuring import CSVDataset from params import TRAIN_BATCH_SIZE, TEST_BATCH_SIZE, LEARNING_RATE, EPOCHS, TRAIN_FILE_PATH, TEST_FILE_PATH
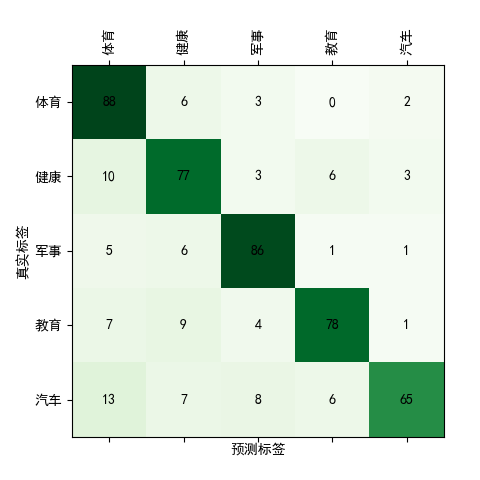
# model train classModelTrainer(object): # evaluate the model @staticmethod defevaluate_model(test_dl, model): predictions, actuals = [], [] for i, (inputs, targets) inenumerate(test_dl): # evaluate the model on the test set yhat = model(inputs) # retrieve numpy array yhat = yhat.detach().numpy() actual = targets.numpy() # convert to class labels yhat = argmax(yhat, axis=1) # reshape for stacking actual = actual.reshape((len(actual), 1)) yhat = yhat.reshape((len(yhat), 1)) # store predictions.append(yhat) actuals.append(actual) predictions, actuals = vstack(predictions), vstack(actuals) # calculate accuracy acc = accuracy_score(actuals, predictions) return acc
# Model Training, evaluation and metrics calculation deftrain(self, model): # calculate split train = CSVDataset(TRAIN_FILE_PATH) test = CSVDataset(TEST_FILE_PATH) # prepare data loaders train_dl = DataLoader(train, batch_size=TRAIN_BATCH_SIZE, shuffle=True) test_dl = DataLoader(test, batch_size=TEST_BATCH_SIZE)
# Define optimizer optimizer = Adam(model.parameters(), lr=LEARNING_RATE) # Starts training phase for epoch inrange(EPOCHS): # Starts batch training for x_batch, y_batch in train_dl: y_batch = y_batch.long() # Clean gradients optimizer.zero_grad() # Feed the model y_pred = model(x_batch) # Loss calculation loss = CrossEntropyLoss()(y_pred, y_batch) # Gradients calculation loss.backward() # Gradients update optimizer.step()
if __name__ == '__main__': model = TextClassifier() # 统计参数量 num_params = sum(param.numel() for param in model.parameters()) print(num_params) ModelTrainer().train(model) torch.save(model, 'sougou_mini_cls.pth')
text = '盖世汽车讯,特斯拉去年击败了宝马,夺得了美国豪华汽车市场的桂冠,并在今年实现了开门红。1月份,得益于大幅降价和7500美元美国电动汽车税收抵免,特斯拉再度击败宝马,蝉联了美国豪华车销冠,并且注册量超过了排名第三的梅赛德斯-奔驰和排名第四的雷克萨斯的总和。根据Experian的数据,在所有豪华品牌中,1月份,特斯拉在美国的豪华车注册量为49,917辆,同比增长34%;宝马的注册量为31,070辆,同比增长2.5%;奔驰的注册量为23,345辆,同比增长7.3%;雷克萨斯的注册量为23,082辆,同比下降6.6%。奥迪以19,113辆的注册量排名第五,同比增长38%。凯迪拉克注册量为13,220辆,较去年同期增长36%,排名第六。排名第七的讴歌的注册量为10,833辆,同比增长32%。沃尔沃汽车排名第八,注册量为8,864辆,同比增长1.8%。路虎以7,003辆的注册量排名第九,林肯以6,964辆的注册量排名第十。'