本文将会介绍机器学习领域的自动化超参优化软件框架——Optuna,它能在很大程度上让我们专注于模型实现,因为它让超参优化变得更加简洁、高效!
Optuna 介绍
Optuna
是一个特别为机器学习设计的开源的自动超参数优化软件框架(hyperparameter
optimization framework)。它具有命令式的, define-by-run 风格的
API。由于这种 API 的存在, 用 Optuna 编写的代码模块化程度很高, Optuna
的用户因此也可以动态地构造超参数的搜索空间。

Optuna的优点如下:
轻量级、多功能和跨平台架构:只需少量依赖,
简单安装完成后便可处理各种任务.
Python 式的搜索空间:利用熟悉的 Python 语法,
如条件语句和循环来定义搜索空间.
高效的优化算法:采用了最先进的超参数采样和最有效的对无望 trial
进行剪枝的算法.
易用的并行优化:仅需少量甚至无需代码修改便可将 study
扩展到数十甚至数百个 worker 上.
便捷的可视化:查询优化记录.
Optuna轻松支持多种深度学习工具,比如PyTorch, TensorFlow,
Keras, MXNet, Scikit-Learn, Chainer, LightGBM等。
Optuna中的基本概念有objective(目标函数)、trail(单次实验)、study(研究)。objective是优化程序的目标函数,一般取最大化(maximize)或最小化(minimize),支持单目标或多目标函数;trail是目标函数的单次执行过程,也就是一次单独的实验;study是基于目标函数的优化过程。
下面我们将介绍三个基本的例子,来体会Optuna的强大之处!
简单例子
在这个例子中,我们优化函数f(x)=x*x-2*x+1,
其中x的取值范围为-3到3的浮点数。
1
2
3
4
5
6
7
8
9
10
|
import optuna
def objective(trial):
x = trial.suggest_float('x', -3, 3)
return x ** 2 - 2 * x + 1
study = optuna.create_study()
study.optimize(objective, n_trials=10)
|
取目标函数进行最小化优化,查看最优参数和最优值:
1
2
3
4
| >>> study.best_params
{'x': 0.8293099933595993}
>>> study.best_value
0.02913507836689999
|
查看10次实验过程,表格如下:
1
2
3
|
df = study.trials_dataframe()
df
|
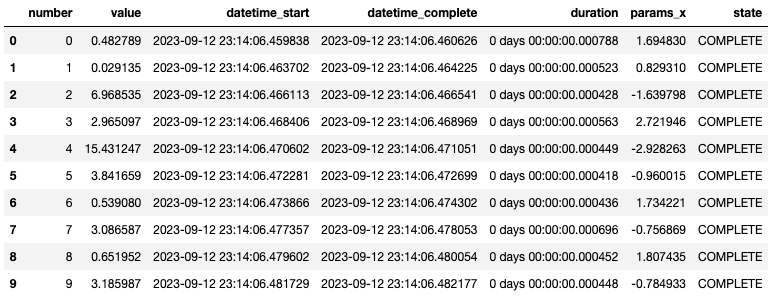 实验结果
实验结果
如果我们在create_study中将目标函数的优化方向(direction)改为最大化,此时查看最优参数和最优值:
1
2
3
4
5
6
7
| study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=10)
>>> study.best_params
{'x': -2.911470602812437}
>>> study.best_value
15.299602276665889
|
机器学习例子
Optuna可支持在机器学习中进行超参优化,如下面的例子,我们对iris数据集,使用SVC和Random
Forest进行分类模型的参数优化,优化的目标函数为K折划分后的验证集的预测准确率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import optuna
import sklearn.datasets
import sklearn.ensemble
import sklearn.model_selection
import sklearn.svm
def objective(trial):
iris = sklearn.datasets.load_iris()
x, y = iris.data, iris.target
classifier_name = trial.suggest_categorical("classifier", ["SVC", "RandomForest"])
if classifier_name == "SVC":
svc_c = trial.suggest_float("svc_c", 1e-10, 1e10, log=True)
classifier_obj = sklearn.svm.SVC(C=svc_c, gamma="auto")
else:
rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32, log=True)
classifier_obj = sklearn.ensemble.RandomForestClassifier(
max_depth=rf_max_depth, n_estimators=10
)
score = sklearn.model_selection.cross_val_score(classifier_obj, x, y, n_jobs=-1, cv=3)
accuracy = score.mean()
return accuracy
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
|
查看最好的实验记录:
1
2
| >>> study.best_trial
FrozenTrial(number=43, state=TrialState.COMPLETE, values=[0.9866666666666667], datetime_start=datetime.datetime(2023, 9, 13, 1, 32, 49, 300321), datetime_complete=datetime.datetime(2023, 9, 13, 1, 32, 49, 329775), params={'classifier': 'SVC', 'svc_c': 4.63942008536747}, user_attrs={}, system_attrs={}, intermediate_values={}, distributions={'classifier': CategoricalDistribution(choices=('SVC', 'RandomForest')), 'svc_c': FloatDistribution(high=10000000000.0, log=True, low=1e-10, step=None)}, trial_id=43, value=None)
|
Optuna也支持可视化,提供了可视化工具optuna
dashboard
。我们只需对上面的代码做些许改造,将实验结果储存在sqlite数据库中。
1
2
| study = optuna.create_study(study_name='iris',direction="maximize",storage='sqlite:///db.sqlite3')
study.optimize(objective, n_trials=100)
|
运行完毕后,输入命令行optuna-dashboard sqlite:///db.sqlite3,在浏览器中输入127.0.0.1:8080,即可在页面中可视化地查看实验中的各项数据。
也可以在Optuna
dashboard官方可视化页面中查看,只需要将sqlite3文件上传即可,页面如下:
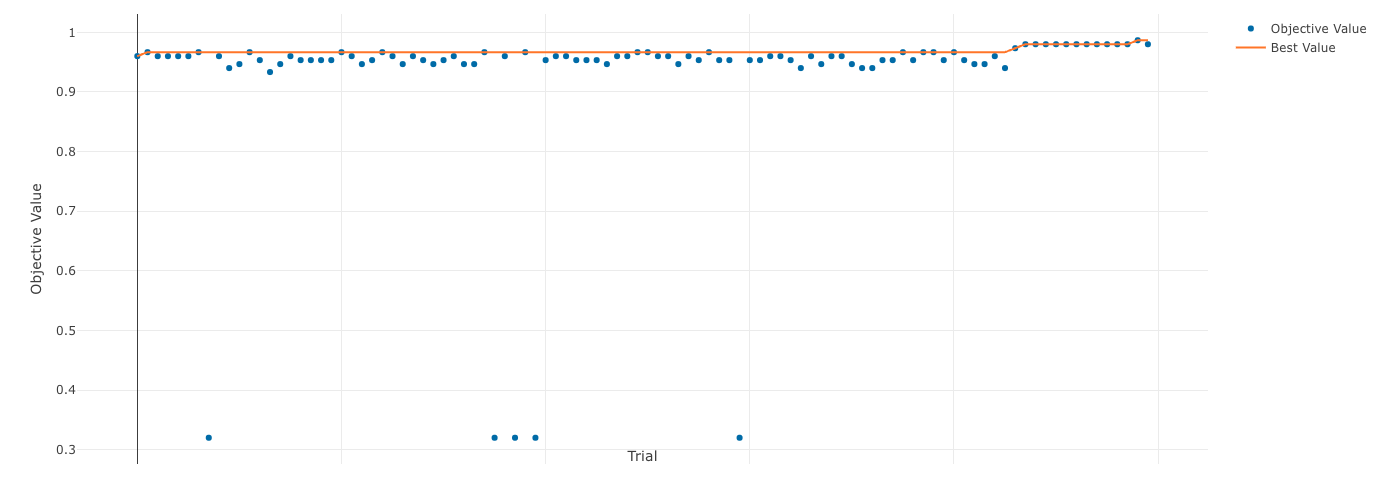 可视化结果
可视化结果
NLP模型例子
PyTorch也提供了对Optuna很好的支持,除了上述的objective,
trail模式,PyTorch还提供了内置代码支持Optuna。
我们以文章NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调
中的文本分类模型训练为例,介绍在PyToch中如何支持Optuna。
预训练模型改为 ckiplab/bert-tiny-chinese
.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import datasets
from transformers import AutoTokenizer, DataCollatorWithPadding
checkpoint = 'ckiplab/bert-tiny-chinese'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
data_files = {"train": "./sougou/train.csv", "test": "./sougou/test.csv"}
raw_datasets = datasets.load_dataset("csv", data_files=data_files, delimiter=",")
def tokenize_function(sample):
return tokenizer(sample['text'], max_length=128, truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=5)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from transformers import Trainer, TrainingArguments
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted')
acc = accuracy_score(labels, preds)
return {'f1': f1}
training_args = TrainingArguments(output_dir='bert_tiny_sougou_trainer_128',
evaluation_strategy="epoch",
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
learning_rate=5e-5,
num_train_epochs=5,
warmup_ratio=0.2,
logging_dir='./sougou_train_logs',
logging_strategy="epoch",
save_strategy="epoch",
report_to="tensorboard")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| def hp_space(trial):
return {"num_train_epochs": trial.suggest_int("num_train_epochs", 2, 10),
"learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-3 ,log=True)}
def model_init():
return AutoModelForSequenceClassification.from_pretrained(
checkpoint,
num_labels=5
)
trainer = Trainer(
model_init=model_init,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
best_run = trainer.hyperparameter_search(n_trials=50,
direction="maximize",
hp_space=hp_space)
|
bert_run是PyTorch中的transformers.trainer_utils中的BestRun,参数为run_id,
objective, hyperparameters, 查看结果如下:
1
2
3
4
5
6
7
8
| >>> for k,v in best_run.hyperparameters.items():
>>> print(k, v)
num_train_epochs 10
learning_rate 8.26383331124286e-05
>>> best_run.run_id
5
>>> best_run.objective
0.933096723776579
|
由上可知,在第5次实验中,num_train_epochs 和 learning_rate
的参数取值使得模型的指标最好,F1为0.9331。
总结
推荐阅读
欢迎关注我的公众号
NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
