PyTorch入门(六)使用Transformer模型进行中文文本分类
在文章PyTorch入门(五)使用CNN模型进行中文文本分类中,笔者介绍了如何在PyTorch中使用CNN模型进行中文文本分类。本文将会使用Transformer模型实现中文文本分类。
本文将会使用相同的数据集。文本预处理已经在文章PyTorch入门(五)使用CNN模型进行中文文本分类中介绍,本文使用Transformer模型的Encoder部分,Transformer模型如图:
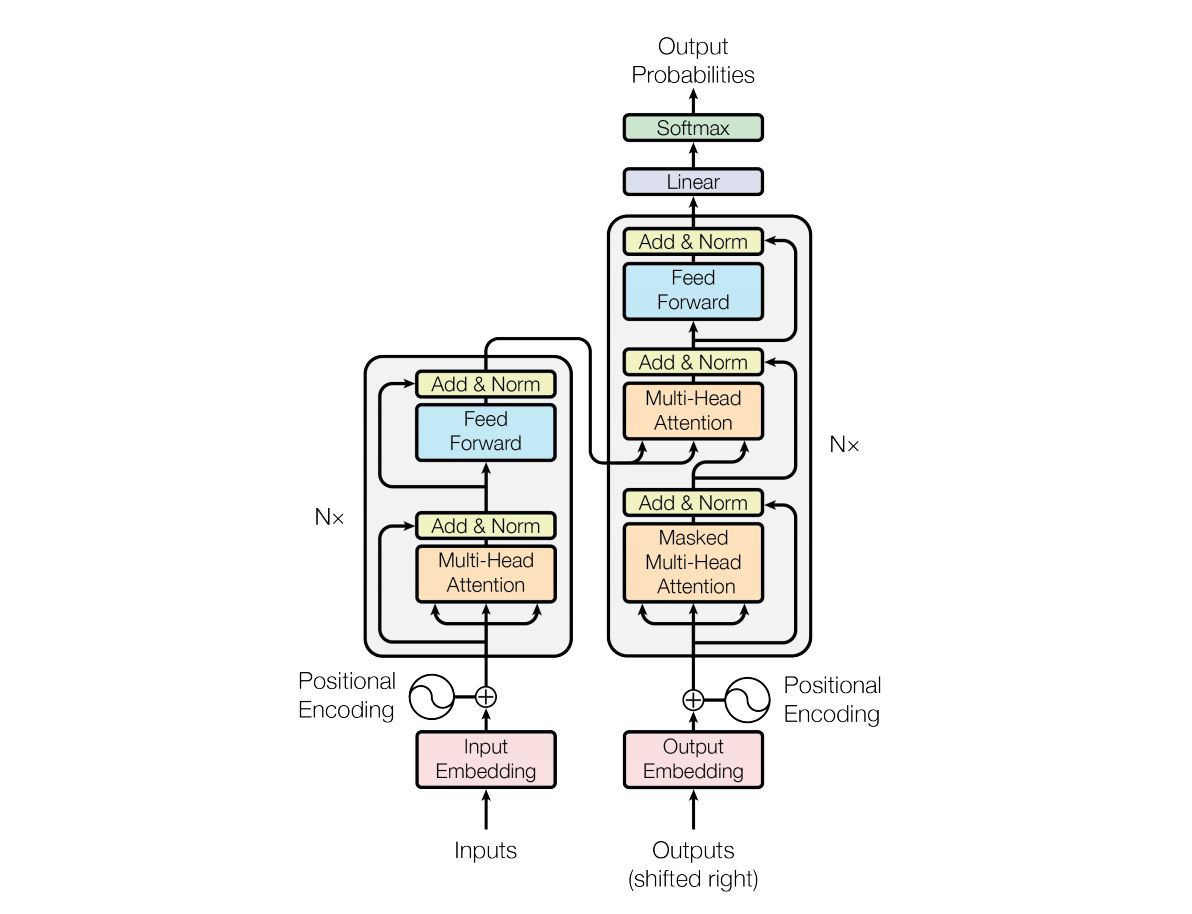
使用Transformer的Encoder部分建立文本分类模型,Python代码如下:
1 | |
需要注意的是,Encoder部分的位置编码(PositionalEncoding类)需要自己实现,因为PyTorch中没有实现。
设置模型参数如下:
- 文字总数为5500
- 文本长度(SENT_LENGTH)为200
- 词向量维度(EMBEDDING_SIZE)为128
- Transformer的Encoder层数(num_layers)为1
- 学习率(learning rate)为0.01
- 训练轮数(epoch)为10
- 批量大小(batch size)为32
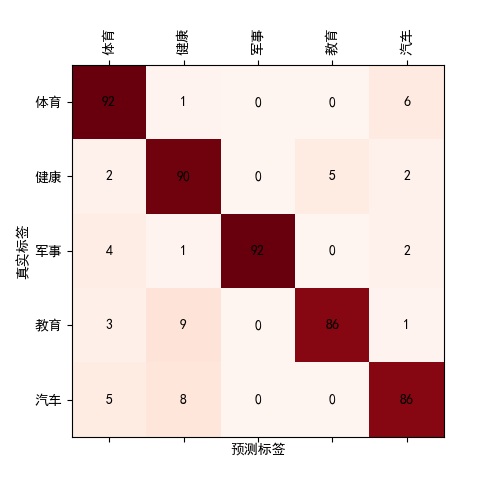
进行模型训练,得到在验证集上的结果为:accuracy=0.9010, precision=0.9051, recall=0.9010, f1-score=0.9018, 混淆矩阵为:
参数影响
我们考察模型参数对模型在验证集上的表现的影响。
- 考察句子长度对模型表现的影响
保持其它参数不变,设置文本长度(SENT_LENGTH)分别为200,256,300,结果如下:
| 文本长度 | accuracy | precision | recall | f1-score |
|---|---|---|---|---|
| 200 | 0.9010 | 0.9051 | 0.9010 | 0.9018 |
| 256 | 0.8990 | 0.9019 | 0.8990 | 0.8977 |
| 300 | 0.8788 | 0.8824 | 0.8788 | 0.8774 |
- 考察词向量维度对模型表现的影响
设置文本长度(SENT_LENGTH)为200,保持其它参数不变,设置词向量维度为32, 64, 128,结果如下:
| 词向量维度 | accuracy | precision | recall | f1-score |
|---|---|---|---|---|
| 32 | 0.6869 | 0.7402 | 0.6869 | 0.6738 |
| 64 | 0.7576 | 0.7629 | 0.7576 | 0.7518 |
| 128 | 0.9010 | 0.9051 | 0.9010 | 0.9018 |
| 256 | 0.9212 | 0.9238 | 0.9212 | 0.9213 |
从中,我们可以发现,文本长度对模型表现的影响不如词向量维度对模型表现的影响大,当然,这是相对而言,因为文本长度一直保持在200以上,如果文本长度下降很多的话,模型表现会迅速下降。
总结
本文介绍了如何使用Transformer模型进行中文文本分类,并考察了各重要参数对模型表现的影响。
本项目已上传至Github,访问网址为:https://github.com/percent4/pytorch_transformer_chinese_text_classification
参考文献
- Language Modeling with nn.Transformer and TorchText: https://pytorch.org/tutorials/beginner/transformer_tutorial.html
- The Annotated Transformer: http://nlp.seas.harvard.edu/annotated-transformer/

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
