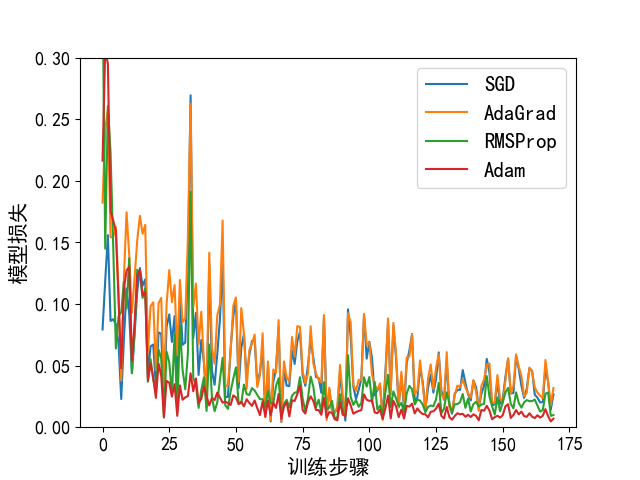
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
import matplotlib.pyplot as plt
import torch
import torch.nn
import torch.utils.data as Data
from torch.utils.data import Dataset
from matplotlib import rcParams
rcParams['font.family'] = 'SimHei'
x = torch.unsqueeze(torch.linspace(-1, 1, 500), dim=1)
y = x.pow(3)
lr = 0.01
batch_size = 15
epoch = 5
torch.manual_seed(1234)
class MyDataset(Dataset):
def __init__(self, x, y):
self.X = x
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return [self.X[idx], self.y[idx]]
loader = Data.DataLoader(dataset=MyDataset(x, y),
batch_size=batch_size,
shuffle=True,
num_workers=2)
class Net(torch.nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(Net, self).__init__()
self.hidden_layer = torch.nn.Linear(n_input, n_hidden)
self.output_layer = torch.nn.Linear(n_hidden, n_output)
def forward(self, input):
x = torch.relu(self.hidden_layer(input))
output = self.output_layer(x)
return output
def train():
net_sgd = Net(1, 10, 1)
net_adagrad = Net(1, 10, 1)
net_rmsprop = Net(1, 10, 1)
net_adam = Net(1, 10, 1)
nets = [net_sgd, net_adagrad, net_rmsprop, net_adam]
opt_sgd = torch.optim.SGD(net_sgd.parameters(), lr=lr)
opt_momentum = torch.optim.Adagrad(net_adagrad.parameters(), lr=lr, lr_decay=0)
opt_rmsprop = torch.optim.RMSprop(net_rmsprop.parameters(), lr=lr, alpha=0.9)
opt_adam = torch.optim.Adam(net_adam.parameters(), lr=lr, betas=(0.9, 0.99))
optimizers = [opt_sgd, opt_momentum, opt_rmsprop, opt_adam]
loss_func = torch.nn.MSELoss()
losses = [[], [], [], []]
for i_epoch in range(epoch):
for step, (batch_x, batch_y) in enumerate(loader):
for net, optimizer, loss_list in zip(nets, optimizers, losses):
pred_y = net(batch_x)
loss = loss_func(pred_y, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss.data.numpy())
plt.figure()
labels = ['SGD', 'AdaGrad', 'RMSProp', 'Adam']
for i, loss in enumerate(losses):
plt.plot(loss, label=labels[i])
plt.legend(loc='upper right', fontsize=15)
plt.tick_params(labelsize=13)
plt.xlabel('训练步骤', size=15)
plt.ylabel('模型损失', size=15)
plt.ylim((0, 0.3))
plt.savefig('optimizer_comparison.png')
if __name__ == '__main__':
train()
|