Redis进阶(一)使用Redis实现分布式锁
本文将会介绍如何使用Redis来实现分布式锁,以及分布式锁的两个应用场景。
前言
在文章Redis快速入门,笔者介绍了Redis的基本数据结构和使用方法,可以作为初学者Redis入门文章。
笔者最近在使用定时任务的时候,发现一个问题:如果多台机器同时部署了同一个定时任务,则会出现同一资源被重复消费的问题。
解决的方案是使用分布式锁。那么,何为分布式锁?
分布式锁,顾名思义,就是在分布式环境下使用的锁,通过锁解决控制共享资源访问
的问题,来保证只有一个线程可以访问被保护的资源。用于实现分布式锁的组件通常都会具备以下的一些特性:
- 互斥性:提供分布式环境下的互斥,一个事件在同一个时间内只能被一个线程执行,这当然是分布式锁最基本的特性。
- 自动释放:为了应对分布式系统中各实例因通信故障导致锁不能释放的问题,自动释放的特性通常也是很有必要的。
- 分区容错性:应用在分布式系统的组件,具备分区容错性也是一项重要的特性,否则就会成为整个系统的瓶颈。
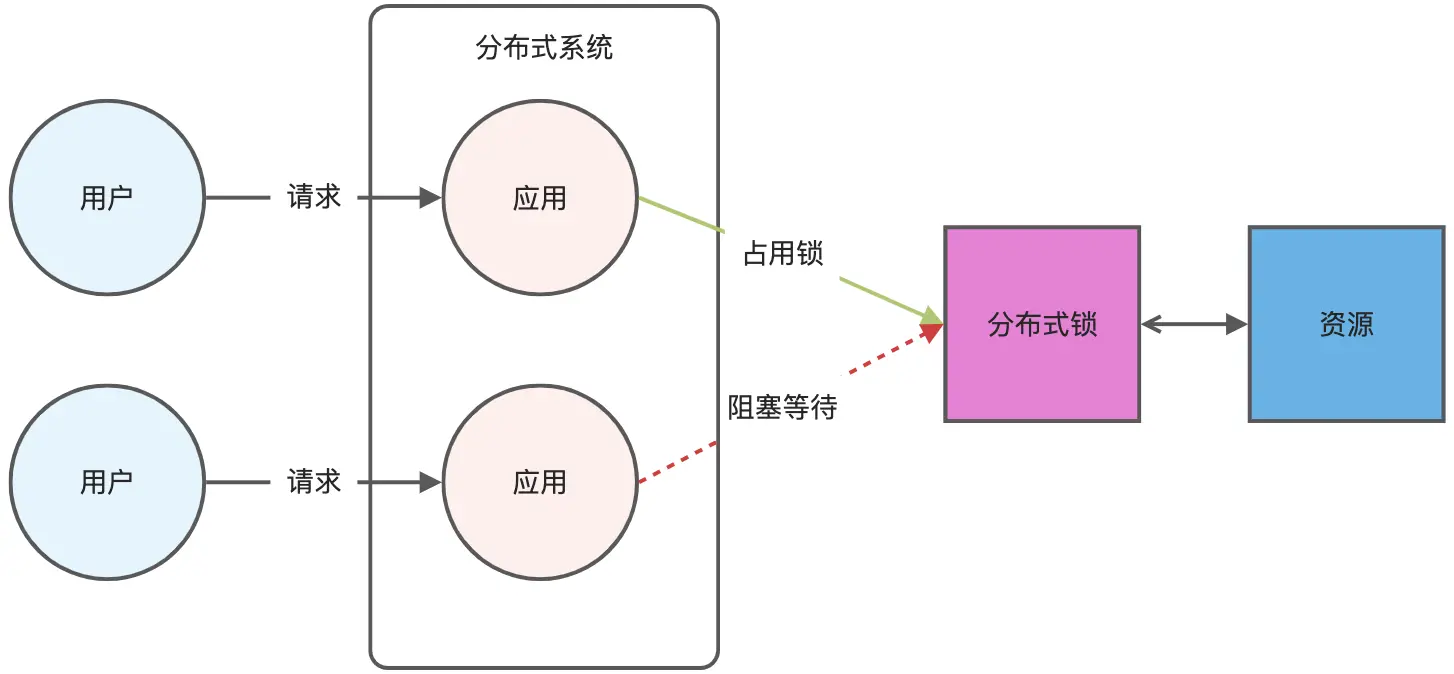
有多种方案可以实现分布式锁:
- 基于数据库实现
- 基于Zookeeper实现
- 基于Redis实现
本文将会重点介绍如何使用Redis来实现分布式锁。
分布式锁的使用场景列举如下:
防止缓存击穿 比如查询一个热点数据,如果缓存中没有,就会有大量请求同时去查数据库,加大数据库压力。加锁可以保证同一时间只有一个请求查数据库,其他请求等待或快速返回。
保证任务的唯一执行 比如定时任务在多个实例部署时,防止同一个任务被多个实例重复执行。加锁可以确保同一时刻,只有一个实例在执行。
控制并发资源 比如购买库存、发放优惠券、下单等高并发场景,需要保证库存扣减或资源分配的正确性,加锁能避免超卖或重复领取的问题。
跨系统、跨服务协调 在微服务架构中,不同服务之间可能需要协调某些操作,比如多个服务同时对一条数据进行修改,这时就需要分布式锁来保证一致性。
避免重复提交 用户短时间内重复提交相同的请求(比如支付按钮连续点击),可以通过加锁来防止后端执行两次。
主备切换场景 比如分布式系统中,某些服务需要通过抢占锁来决定谁是主节点(Leader Election)。
本文将会介绍分布式锁在保证任务的唯一执行和避免重复提交这两个场景中的应用。
Redis基础命令
在介绍如何使用Redis来实现分布式锁前,我们有必要先了解实现分布式锁的Redis基础命令。
- SETNX命令
SETNX 是 set if not exists 的缩写,当且仅当 key 不存在时,则设置 value 给这个key。若给定的 key 已经存在,则 SETNX 不做任何动作。其返回值1表示该进程执行成功,将key值设置为value;返回值0表明该key已存在。
1 | |
如上所示,第一次运行SETNX能成功,第二次运行时demo_task这个key已存在,返回值为0.
- GET, DEL命令
GET命令获取key的值,如果存在,则返回;如果不存在,则返回nil.
DEL命令为删除对应key.
1 | |
- 设置超时
超时在分布式锁中就是重置,避免因为各种原因导致锁长时间无法释放,做法就是给key加个超时时间。
1 | |
上述命令设置demo_task这个key,并设置超时时间为3600秒。但上述操作分为两步执行,不是原子命令。
为了保证执行时的原子性,Redis 官方扩展了 SET 命令,既能满足获取对象,又能保证设置超时的时间语义。上述命令可以改写成:
1 | |
在上述命令中,NX表明Not Exist, PX表示超时时间,单位毫秒。
Python实现
基于上面的Redis基础命令,我们实现Python来实现分布式锁。需要注意的是,在释放锁(即运行删除命令)的时候,需要对锁进行唯一标识,避免别的程序误删除设置的锁。
下面是Python实现分布式锁的代码(文件名为distribute_key_op.py):
1 | |
运行结果如下:
1 | |
定时任务唯一执行
设想场景:
在MySQL表,存在5条数据,需要设置定时任务,对doc字段进行关键词提取,并将结果保存为JSON文件。
MySQL表中对应数据如下:
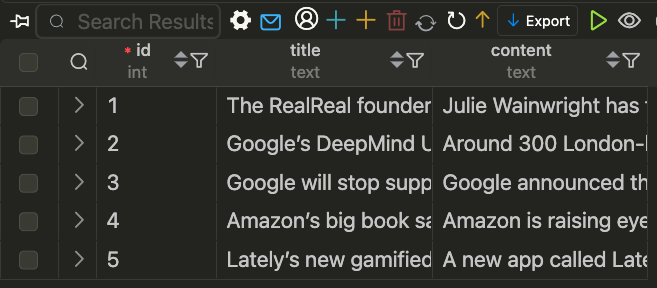
该表使用sqlalchemy模块创建,对应Python代码(mysql_create_table.py)如下:
1 | |
定时任务(cron_doc_tag_1.py)脚本如下:
1 | |
复制该脚本,重命名为cron_doc_tag_1.py,并将文件写入时"task_id"改为 "cron_doc_tag_2"。
同时运行上述两个脚本,则这两个定时任务在20点30分会同时运行,但是,数据库中的每条记录都运行了两次。保存文件内容如下:
1 | |
这并不符合我们的预期,我们的预期是即使这个定时任务部署在多台机器上,或者在不同地方启动时,该定时任务只需要执行一次。
使用分布式锁可以保证我们的定时任务只执行一次。
实现脚本(cron_doc_tag_1_with_lock.py)代码如下:
1 | |
复制该脚本,重命名为cron_doc_tag_2.py,并将文件写入时"task_id"改为 "cron_doc_tag_2"。
同时运行上述两个脚本,cron_doc_tag_1.py的运行结果如下:
1 | |
cron_doc_tag_2.py的运行结果如下:
1 | |
保存文件内容如下:
1 | |
从上面的运行结果,我们可以看出,使用分布式锁可以保证定时任务唯一执行,避免同一资源被重复消费。
短时间内避免重复执行
用户短时间内重复提交相同的请求(比如支付按钮连续点击),可以通过加锁来防止后端重复执行。
设想场景:
用户在短时间内重复点击了支付按钮,那么只有其中一个线程会执行真正的支付操作,而其它线程则不会执行支付操作。
使用分布式锁来避免短时间内重复提交,其Python实现代码如下:
1 | |
输出结果如下:
1 | |
从上面的运行结果可以看出,短时间内同时提交了5次支付请求,但只有Thread-2这个线程在真正执行支付操作,其它线程因为分布式锁的原因没有拿到锁,从而没有执行支付操作。
总结
本文介绍了分布式锁的基础概念和使用场景,结合Redis基础命令,使用Python和Redis实现了分布式锁。
在分布式锁的使用场景中,笔者介绍了如何使用它来保证定时任务的唯一执行,以及如何避免在短时间内重复操作。
后续笔者介绍介绍更多Redis的使用场景,下一篇文章的主题将是如何使用Redis来实现消息队列。
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
