1
2
3
4
5
6
7
8
9
10
11
12
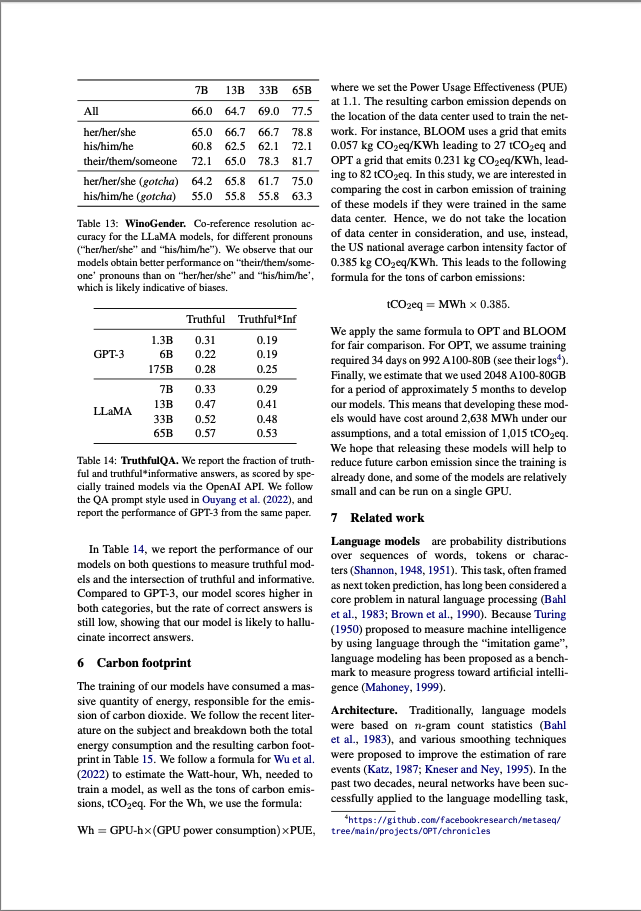
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
|
import cv2
import json
import base64
import pandas as pd
import gradio as gr
from PIL import Image
import requests
from urllib.request import urlretrieve
from uuid import uuid4
from transformers import AutoImageProcessor, TableTransformerForObjectDetection
import torch
from transformers import DetrFeatureExtractor
from transformers import AutoImageProcessor, TableTransformerForObjectDetection
from paddleocr import PaddleOCR
image_processor = AutoImageProcessor.from_pretrained("./models/table-transformer-detection")
detect_model = TableTransformerForObjectDetection.from_pretrained("./models/table-transformer-detection")
structure_model = TableTransformerForObjectDetection.from_pretrained("./models/table-transformer-structure-recognition-v1.1-all")
print(structure_model.config.id2label)
feature_extractor = DetrFeatureExtractor()
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
def paddle_ocr(image_path):
result = ocr.ocr(image_path, cls=True)
ocr_result = []
for idx in range(len(result)):
res = result[idx]
if res:
for line in res:
print(line)
ocr_result.append(line[1][0])
return "".join(ocr_result)
def table_detect(image_box, image_url):
if not image_url:
file_name = str(uuid4())
image = Image.fromarray(image_box).convert('RGB')
else:
image_path = f"./images/{uuid4()}.png"
file_name = image_path.split('/')[-1].split('.')[0]
urlretrieve(image_url, image_path)
image = Image.open(image_path).convert('RGB')
inputs = image_processor(images=image, return_tensors="pt")
outputs = detect_model(**inputs)
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[0]
i = 0
output_images = []
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {detect_model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
region = image.crop(box)
output_image_path = f'./table_images/{file_name}_{i}.jpg'
region.save(output_image_path)
output_images.append(output_image_path)
i += 1
return output_images
def table_ocr(output_images, image_index):
output_image = output_images[int(image_index)][0]
image = Image.open(output_image).convert("RGB")
encoding = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
outputs = structure_model(**encoding)
target_sizes = [image.size[::-1]]
results = feature_extractor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[0]
print(results)
columns = []
rows = []
for i in range(len(results['boxes'])):
_id = results['labels'][i].item()
if _id == 1:
columns.append(results['boxes'][i].tolist())
elif _id == 2:
rows.append(results['boxes'][i].tolist())
sorted_columns = sorted(columns, key=lambda x: x[0])
sorted_rows = sorted(rows, key=lambda x: x[1])
ocr_results = []
for row in sorted_rows:
row_result = []
for col in sorted_columns:
rect = [col[0], row[1], col[2], row[3]]
crop_image = image.crop(rect)
image_path = 'cell.png'
crop_image.save(image_path)
row_result.append(paddle_ocr(image_path=image_path))
print(row_result)
ocr_results.append(row_result)
print(ocr_results)
return ocr_results
if __name__ == '__main__':
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
image_box = gr.Image()
image_urls = gr.TextArea(lines=1, placeholder="Enter image url", label="Images")
image_index = gr.TextArea(lines=1, placeholder="Image Number", label="No")
with gr.Column():
gallery = gr.Gallery(label="Tables", show_label=False, elem_id="gallery", columns=[3], rows=[1], object_fit="contain", height="auto")
detect = gr.Button("Table Detection")
submit = gr.Button("Table OCR")
ocr_outputs=gr.DataFrame(label='Table',
interactive=True,
wrap=True)
detect.click(fn=table_detect,
inputs=[image_box, image_urls],
outputs=gallery)
submit.click(fn=table_ocr,
inputs=[gallery, image_index],
outputs=ocr_outputs)
demo.launch(server_name="0.0.0.0", server_port=50074)
|