本文将详细介绍RAG框架中的各种Retrieve算法,比如BM25, Embedding
Search, Ensemble Search,
Rerank等的评估实验过程与结果。本文是目前除了LlamaIndex官方网站例子之外为数不多的介绍Retrieve算法评估实验的文章。
什么是RAG中的Retrieve?
RAG即Retrieval Augmented
Generation的简称,是现阶段增强使用LLM的常见方式之一,其一般步骤为:
文档划分(Document Split)
向量嵌入(Embedding)
文档获取(Retrieve)
Prompt工程(Prompt Engineering)
大模型问答(LLM)
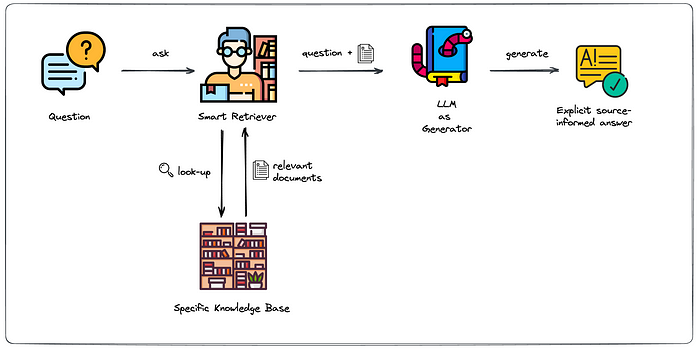
大致的流程图参考如下:
通常来说,可将RAG划分为召回(Retrieve )阶段和答案生成(Answer
Generate )阶段,而效果优化也从这方面入手。针对召回阶段,文档获取是其中重要的步骤,决定了注入大模型的知识背景,常见的召回算法如下:
BM25(又称Keyword Search) :
使用BM24算法找回相关文档,一般对于特定领域关键词效果较好,比如人名,结构名等;Embedding Search :
使用Embedding模型将query和corpus进行文本嵌入,使用向量相似度进行文本匹配,可解决BM25算法的相似关键词召回效果差的问题,该过程一般会使用向量数据库(Vector
Database);Ensemble Search : 融合BM25算法和Embedding
Search的结果,使用RFF算法进行重排序,一般会比单独的召回算法效果好;Rerank :
上述的召回算法一般属于粗召回阶段,更看重性能;Rerank是对粗召回阶段的结果,再与query进行文本匹配,属于Rerank(又称为重排、精排)阶段,更看重效果;
综合上述Retrieve算法的框架示意图如下:
上述的Retrieve算法更有优劣,一般会选择合适的场景进行使用或考虑综合几种算法进行使用。那么,它们的效果具体如何呢?
Retrieve算法评估
那么,如何对Retrieve算法进行具体效果评估呢?
本文将通过构造自有数据集进行测试,分别对上述四种Retrieve算法进行实验,采用Hit Rate和MRR指标进行评估。
在LlamaIndex 官方Retrieve
Evaluation中,提供了对Retrieve算法的评估示例,具体细节可参考如下:
https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
这是现在网上较为权威的Retrieve
Evaluation实验,本文将参考LlamaIndex的做法,给出更为详细的评估实验过程与结果。
Retrieve Evaluation实验的步骤如下:
文档划分:寻找合适数据集,进行文档划分;问题生成:对划分后的文档,使用LLM对文档内容生成问题;召回文本:对生成的每个问题,采用不同的Retrieve算法,得到召回结果;指标评估:使用Hit Rate和MRR指标进行评估
步骤是清晰的,那么,我们来看下评估指标:Hit Rate和MRR。
Hit Rate即命中率,一般指的是我们预期的召回文本(真实值)在召回结果的前k个文本中会出现,也就是Recall@k时,能得到预期文本。一般,Hit Rate越高,就说明召回算法效果越好。
MRR即Mean Reciprocal
Rank,是一种常见的评估检索效果的指标。MRR
是衡量系统在一系列查询中返回相关文档或信息的平均排名的逆数的平均值。例如,如果一个系统对第一个查询的正确答案排在第二位,对第二个查询的正确答案排在第一位,则
MRR 为 (1/2 + 1/1) / 2。
在LlamaIndex中,这两个指标的对应类分别为HitRate和MRR,源代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class HitRate (BaseRetrievalMetric ):"""Hit rate metric.""" str = "hit_rate" def compute ( self, query: Optional [str ] = None , expected_ids: Optional [List [str ]] = None , retrieved_ids: Optional [List [str ]] = None , expected_texts: Optional [List [str ]] = None , retrieved_texts: Optional [List [str ]] = None , **kwargs: Any , ) -> RetrievalMetricResult:"""Compute metric.""" if retrieved_ids is None or expected_ids is None :raise ValueError("Retrieved ids and expected ids must be provided" )any (id in expected_ids for id in retrieved_ids)return RetrievalMetricResult(1.0 if is_hit else 0.0 ,class MRR (BaseRetrievalMetric ):"""MRR metric.""" str = "mrr" def compute ( self, query: Optional [str ] = None , expected_ids: Optional [List [str ]] = None , retrieved_ids: Optional [List [str ]] = None , expected_texts: Optional [List [str ]] = None , retrieved_texts: Optional [List [str ]] = None , **kwargs: Any , ) -> RetrievalMetricResult:"""Compute metric.""" if retrieved_ids is None or expected_ids is None :raise ValueError("Retrieved ids and expected ids must be provided" )for i, id in enumerate (retrieved_ids):if id in expected_ids:return RetrievalMetricResult(1.0 / (i + 1 ),return RetrievalMetricResult(0.0 ,
数据集构造
在文章NLP(六十一)使用Baichuan-13B-Chat模型构建智能文档 笔者介绍了如何使用RAG框架来实现智能文档问答。
以这个项目为基础,笔者采集了日本半导体行业相关的网络文章及其他文档,进行文档划分,导入至ElastricSearch,并使用OpenAI
Embedding获取文本嵌入向量。语料库一共为433个文档片段(Chunk),其中321个与日本半导体行业相关(不妨称之为领域文档)。
还差query数据集。这点是从LlamaIndex官方示例中获取的灵感:使用大模型生成query !
针对上述321个领域文档,使用GPT-4模型生成一个与文本内容相关的问题,即query,Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import pandas as pdfrom llama_index.llms import OpenAIfrom llama_index.schema import TextNodefrom llama_index.evaluation import generate_question_context_pairsimport random42 )"gpt-4" , max_retries=5 )"""\ Context information is below. --------------------- {context_str} --------------------- Given the context information and not prior knowledge. generate only questions based on the below query. You are a university professor. Your task is to set {num_questions_per_chunk} questions for the upcoming Chinese quiz. Questions throughout the test should be diverse. Questions should not contain options or start with Q1/Q2. Questions must be written in Chinese. The expression must be concise and clear. It should not exceed 15 Chinese characters. Words such as "这", "那", "根据", "依据" and other punctuation marks should not be used. Abbreviations may be used for titles and professional terms. """ "../data/doc_qa_dataset.csv" , encoding="utf-8" )for i, row in data_df.iterrows():if len (row["content" ]) > 80 and i > 96 :"content" ])f"node_{i + 1 } " 1 , qa_generate_prompt_tmpl=qa_generate_prompt_tmpl"../data/doc_qa_dataset.json" )
原始数据doc_qa_dataset.csv是笔者从Kibana中的Discover中导出的,使用llama-index模块和GPT-4模型,以合适的Prompt,对每个领域文档生成一个问题,并保存为doc_qa_dataset.json,这就是我们进行Retrieve
Evaluation的数据格式,其中包括queries, corpus, relevant_docs,
mode四个字段。
我们来查看第一个文档及生成的答案,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 { "queries" : { "7813f025-333d-494f-bc14-a51b2d57721b" : "日本半导体产业的现状和影响因素是什么?" , } , "corpus" : { "node_98" : "日本半导体产业在上世纪80年代到达顶峰后就在缓慢退步,但若简单认为日本半导体产业失败了,就是严重误解,今天日本半导体产业仍有非常有竞争力的企业和产品。客观认识日本半导体产业的成败及其背后的原因,对正在大力发展半导体产业的中国,有非常强的参考价值。" , } , "relevant_docs" : { "7813f025-333d-494f-bc14-a51b2d57721b" : [ "node_98" ] , } , "mode" : "text" }
Retrieve算法评估
我们需要评估的Retrieve算法为BM25, Embedding Search, Ensemble Search,
Ensemble +
Rerank,下面将分别就Retriever实现方式、指标评估实验对每种Retrieve算法进行详细介绍。
BM25
BM25的储存采用ElasticSearch,即直接使用ES内置的BM25算法。笔者在llama-index对BaseRetriever进行定制化开发(这也是我们实现自己想法的一种常规方法),对其简单封装,Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from typing import List from elasticsearch import Elasticsearchfrom llama_index.schema import TextNodefrom llama_index import QueryBundlefrom llama_index.schema import NodeWithScorefrom llama_index.retrievers import BaseRetrieverfrom llama_index.indices.query.schema import QueryTypefrom preprocess.get_text_id_mapping import text_node_id_mappingclass CustomBM25Retriever (BaseRetriever ):"""Custom retriever for elasticsearch with bm25""" def __init__ (self, top_k ) -> None :"""Init params.""" super ().__init__()'host' : 'localhost' , 'port' : 9200 }])def _retrieve (self, query: QueryType ) -> List [NodeWithScore]:if isinstance (query, str ):else :'query' : {'match' : {'content' : query.query_str"size" : self.top_k'docs' , body=dsl)if search_result['hits' ]['hits' ]:for record in search_result['hits' ]['hits' ]:'_source' ]['content' ]'_score' ])return result
之后,对top_k结果进行指标评估,Python代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import asyncioimport timeimport pandas as pdfrom datetime import datetimefrom faiss import IndexFlatIPfrom llama_index.evaluation import RetrieverEvaluatorfrom llama_index.finetuning.embeddings.common import EmbeddingQAFinetuneDatasetfrom custom_retriever.bm25_retriever import CustomBM25Retrieverfrom custom_retriever.vector_store_retriever import VectorSearchRetrieverfrom custom_retriever.ensemble_retriever import EnsembleRetrieverfrom custom_retriever.ensemble_rerank_retriever import EnsembleRerankRetrieverfrom custom_retriever.query_rewrite_ensemble_retriever import QueryRewriteEnsembleRetrieverdef display_results (name_list, eval_results_list ):'display.precision' , 4 )"retrievers" : [], "hit_rate" : [], "mrr" : []}for name, eval_results in zip (name_list, eval_results_list):for eval_result in eval_results:"hit_rate" ].mean()"mrr" ].mean()"retrievers" ].append(name)"hit_rate" ].append(hit_rate)"mrr" ].append(mrr)return metric_df"../data/doc_qa_test.json" )"mrr" , "hit_rate" ]for top_k in [1 , 2 , 3 , 4 , 5 ]:f"bm25_top_{top_k} _eval" )1000 )print ("done for bm25 evaluation!" )'cost_time' ] = cost_time_listprint (df.head())f"evaluation_bm25_{datetime.now().strftime('%Y-%m-%d %H:%M:%S' )} .csv" , encoding="utf-8" , index=False )
BM25算法的实验结果如下:
bm25_top_1_eval
0.7975
0.7975
461.277
bm25_top_2_eval
0.8536
0.8255
510.3021
bm25_top_3_eval
0.9003
0.8411
570.6708
bm25_top_4_eval
0.9159
0.845
420.7261
bm25_top_5_eval
0.9408
0.85
388.5961
Embedding Search
BM25算法的实现是简单的。Embedding
Search的较为复杂些,首先需要对queries和corpus进行文本嵌入,这里的Embedding模型使用Openai的text-embedding-ada-002,向量维度为1536,并将结果存入numpy数据结构中,保存为npy文件,方便后续加载和重复使用。
为了避免使用过重的向量数据集,本实验采用内存向量数据集:
faiss 。使用faiss加载向量,index类型选用IndexFlatIP,并进行向量相似度搜索。
Embedding
Search也需要定制化开发Retriever及指标评估,这里不再赘述,具体实验可参考文章末尾的Github项目地址。
Embedding Search的实验结果如下:
embedding_top_1_eval
0.6075
0.6075
67.6837
embedding_top_2_eval
0.6978
0.6526
60.8449
embedding_top_3_eval
0.7321
0.6641
59.9051
embedding_top_4_eval
0.7788
0.6758
63.5488
embedding_top_5_eval
0.7944
0.6789
67.7922
注意:
这里的召回时间花费比BM25还要少,完全得益于我们已经存储好了文本向量,并使用faiss进行加载、查询。
Ensemble Search
Ensemble Search融合BM25算法和Embedding
Search算法,针对两种算法召回的top_k个文档,使用RRF算法进行重新排序,再获取top_k个文档。RRF算法是经典且优秀的集成排序算法,这里不再展开介绍,后续专门写文章介绍。
Ensemble Search的实验结果如下:
ensemble_top_1_eval
0.7009
0.7009
1072.7379
ensemble_top_2_eval
0.8536
0.7741
1088.8782
ensemble_top_3_eval
0.8941
0.7928
980.7949
ensemble_top_4_eval
0.919
0.8017
935.1702
ensemble_top_5_eval
0.9377
0.8079
868.299
Ensemble + Rerank
如果还想在Ensemble
Search的基础上再进行效果优化,可考虑加入Rerank算法。常见的Rerank模型有Cohere(API调用),BGE-Rerank(开源模型)等。本文使用Cohere
Rerank API.
Ensemble + Rerank的实验结果如下:
ensemble_rerank_top_1_eval
0.8349
0.8349
2140632.4041
ensemble_rerank_top_2_eval
0.9034
0.8785
2157657.2871
ensemble_rerank_top_3_eval
0.9346
0.9008
2200800.936
ensemble_rerank_top_4_eval
0.947
0.9078
2150398.7348
ensemble_rerank_top_5_eval
0.9657
0.9099
2149122.9382
指标可视化及分析
指标可视化
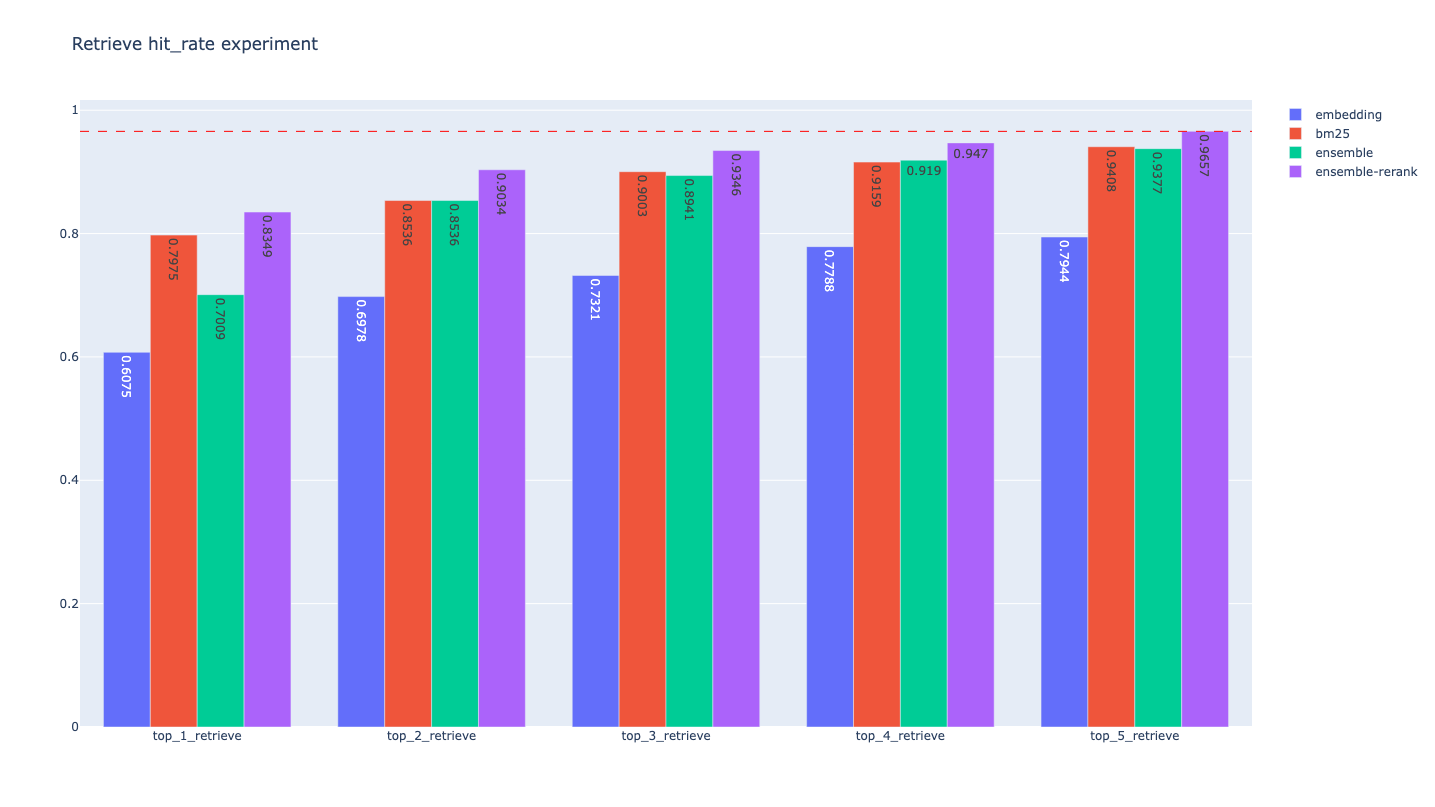
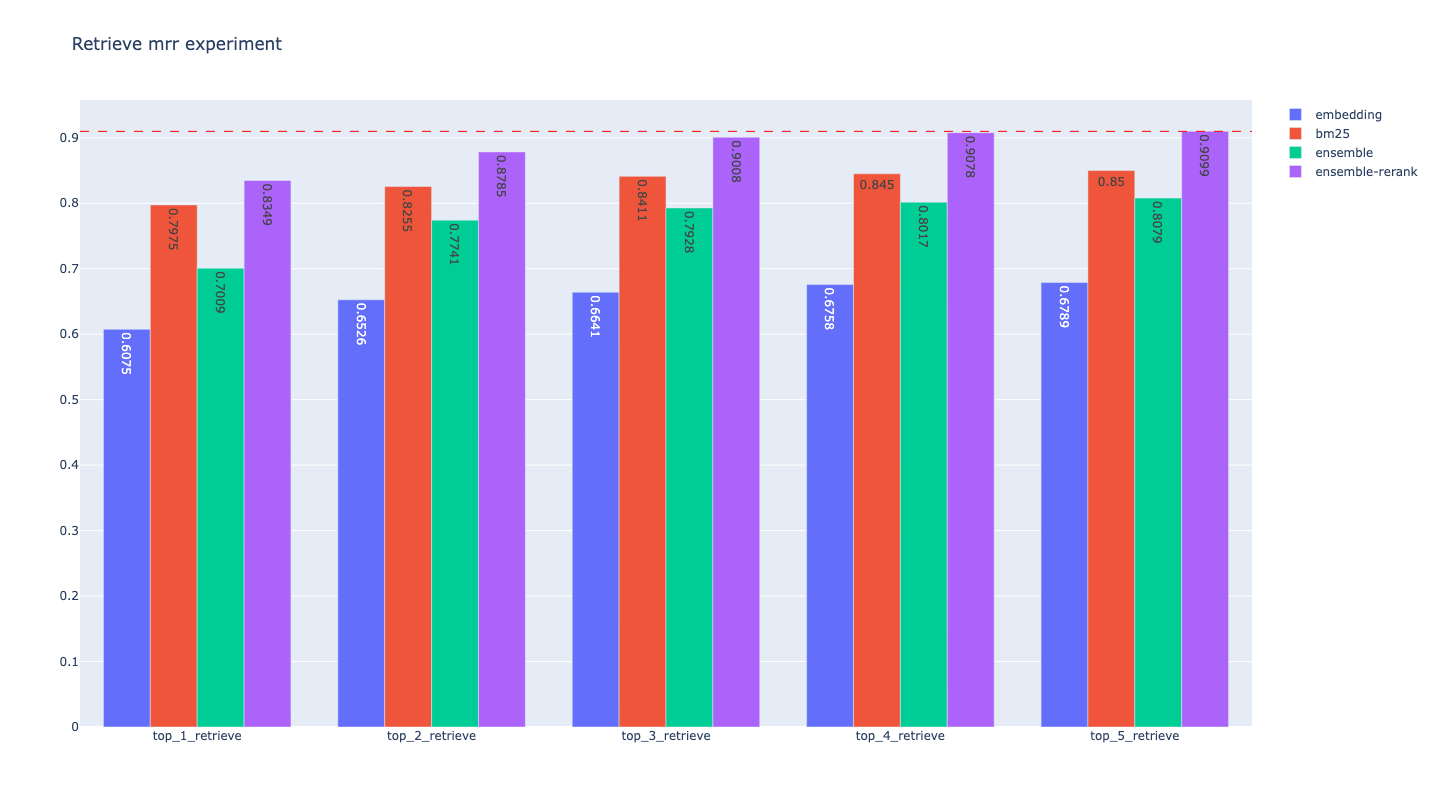
上述的评估结果不够直观,我们使用Plotly模块绘制指标的条形图,结果如下:
Hit Rate
MRR
指标分析
我们对上述统计图进行指标分析,可得到结论如下:
对于每种Retrieve算法,随着k的增加,top_k的Hit
Rate指标和MRR指标都有所增加,即检索效果变好,这是显而易见的结论;
就总体检索效果而言,Ensemble + Rerank > Ensemble >
单独的Retrieve
本项目中就单独的Retrieve算法而言,BM25的检索效果比Embedding
Search好(可能与生成的问答来源于文档有关),但这不是普遍结论,两种算法更有合适的场景
加入Rerank后,检索效果可获得一定的提升,以top_3评估结果来说,ensemble的Hit
Rate为0.8941,加入Rerank后为0.9346,提升约4%
总结
本文详细介绍了RAG框架,并结合自有数据集对各种Retrieve算法进行评估。笔者通过亲身实验和编写Retriever代码,深入了解了RAG框架中的经典之作LlamaIndex,同时,本文也是难得的介绍RAG框架Retrieve阶段评估实验的文章。
本文的所有过程及指标结果已开源至Github,网址为:https://github.com/percent4/embedding_rerank_retrieval
.
后续,笔者将在此项目基础上,验证各种优化RAG框架Retrieve效果的手段,比如Query
Rewrite, Query Transform, HyDE等,这将是一个获益无穷的项目啊!
参考文献
Retrieve
Evaluation官网文章:https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
Retrieve Evaluation
Colab上的代码:https://colab.research.google.com/drive/1TxDVA__uimVPOJiMEQgP5fwHiqgKqm4-?usp=sharing
LlamaIndex官网:https://docs.llamaindex.ai/en/stable/index.html
RetrieverEvaluator in LlamaIndex:
https://docs.llamaindex.ai/en/stable/module_guides/evaluating/usage_pattern_retrieval.html
NLP(六十一)使用Baichuan-13B-Chat模型构建智能文档:
https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247485425&idx=1&sn=bd85ddfce82d77ceec5a66cb96835400&chksm=fcb9be61cbce37773109f9703c2b6c4256d5037c8bf4497dfb9ad0f296ce0ee4065255954c1c&token=1977141018&lang=zh_CN#rd
NLP(六十九)智能文档助手升级:
https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247485609&idx=1&sn=f8337b4822b1cdf95a586af6097ef288&chksm=fcb9b139cbce382f735e4c119ade8084067cde0482910c72767f36a29e7291385cbe6dfbd6a9&payreadticket=HBB91zkl4I6dXpw0Q4OcOF8ECZz0pS9kOGHJqycwrN7jFWHyUOCBe7sWFWytD7_9wo_NzcM#rd
NLP(八十一)智能文档问答助手项目改进:
https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486103&idx=1&sn=caa204eda0760bab69b7e40abff8e696&chksm=fcb9b307cbce3a1108d305ec44281e3446241e90e9c17d62dd0b6eaa48cba5e20d31f0129584&token=1977141018&lang=zh_CN#rd
欢迎关注我的公众号
NLP奇幻之旅 ,原创技术文章第一时间推送。
欢迎关注我的知识星球“自然语言处理奇幻之旅 ”,笔者正在努力构建自己的技术社区。