vLLM入门(一)初始vLLM
本文将会介绍大模型部署工具vLLM及其使用方法。
介绍与安装
vLLM是伯克利大学LMSYS组织开源的大语言模型高速推理框架,旨在极大地提升实时场景下的语言模型服务的吞吐与内存使用效率。vLLM是一个快速且易于使用的库,用于
LLM 推理和服务,可以和HuggingFace
无缝集成。vLLM利用了全新的注意力算法「PagedAttention」,有效地管理注意力键和值。
![]()
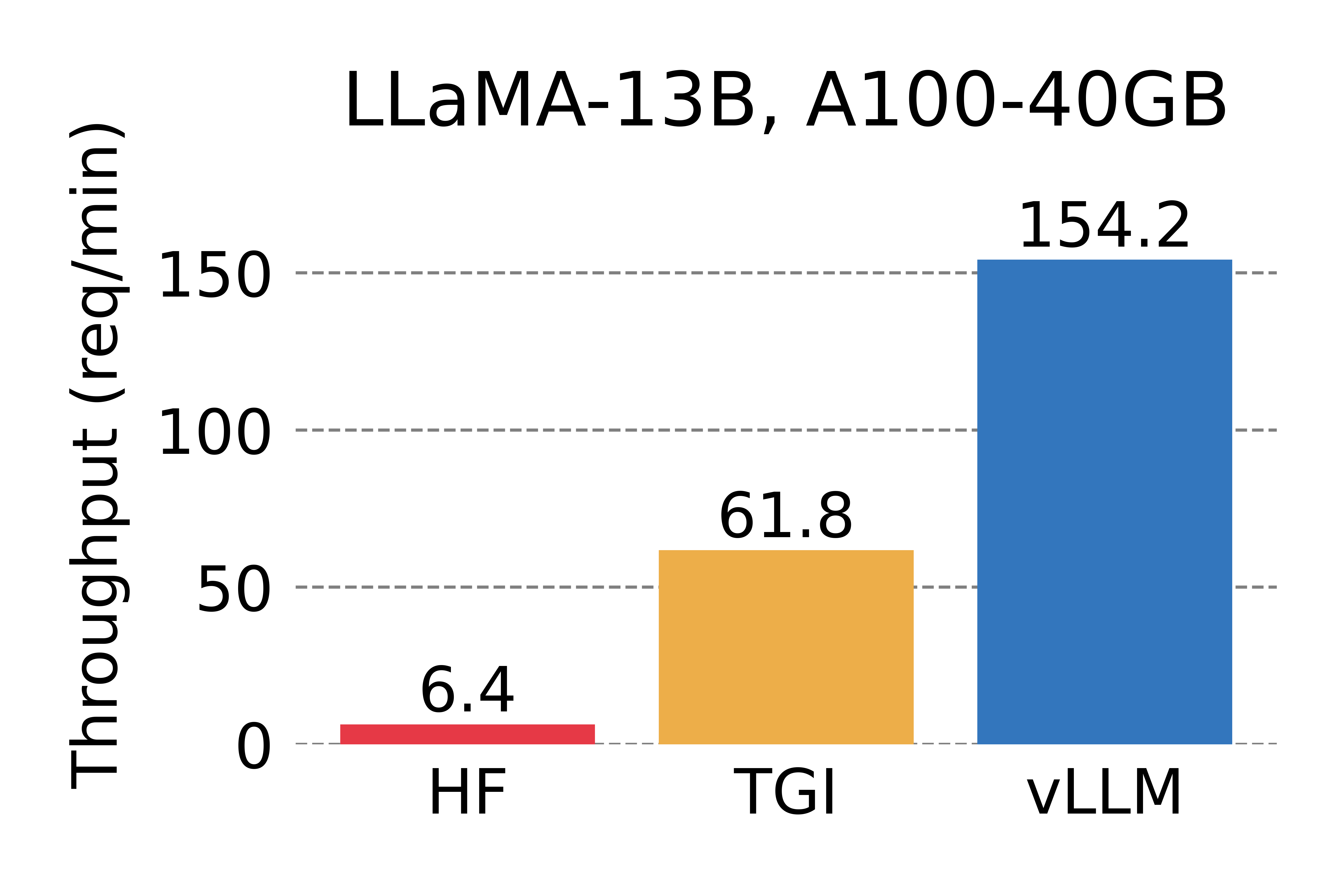
在吞吐量方面,vLLM的性能比HuggingFace Transformers(HF)高出 24 倍,文本生成推理(TGI)高出3.5倍。
安装命令:
pip3 install vllm
本文使用的Python第三方模块的版本如下:
1 | |
vLLM初步使用
线下批量推理
线下批量推理:为输入的prompts列表,使用vLLM生成答案
1 | |
INFO 01-18 08:13:26 llm_engine.py:70] Initializing an LLM engine with config: model='/data-ai/model/llama2/llama2_hf/Llama-2-13b-chat-hf', tokenizer='/data-ai/model/llama2/llama2_hf/Llama-2-13b-chat-hf', tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=4096, download_dir=None, load_format=auto, tensor_parallel_size=1, quantization=None, enforce_eager=False, seed=0)
INFO 01-18 08:13:37 llm_engine.py:275] # GPU blocks: 3418, # CPU blocks: 327
INFO 01-18 08:13:39 model_runner.py:501] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
INFO 01-18 08:13:39 model_runner.py:505] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode.
INFO 01-18 08:13:44 model_runner.py:547] Graph capturing finished in 5 secs.1 | |
1 | |
Processed prompts: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 11.76it/s]
Prompt: 'Hello, my name is', Generated text: " Sherry and I'm a stay at home mom of three beautiful children."
Prompt: 'The president of the United States is', Generated text: ' one of the most powerful people in the world, and yet, many people do'
Prompt: 'The capital of France is', Generated text: ' Paris. This is a fact that is well known to most people, but there'
Prompt: 'The future of AI is', Generated text: ' likely to be shaped by a combination of technological advancements and soci'API Server服务
vLLM可以部署为API服务,web框架使用FastAPI。API服务使用AsyncLLMEngine类来支持异步调用。
使用命令 python -m vllm.entrypoints.api_server --help
可查看支持的脚本参数。
API服务启动命令:
1 | |
输入:
1 | |
输出:
1 | |
OpenAI风格的API服务
启动命令:
1 | |
还可指定对话模板(chat-template)。
查看模型
1 | |
输出:
1 | |
text completion
输入:
1 | |
输出:
1 | |
chat completion
输入:
1 | |
输出:
1 | |
vLLM实战
大模型简单问答
vLLM暂不支持同时部署多个大模型,因此,笔者采用一次部署一个模型,部署多次的方法来实现部署多个大模型,这里采用llama-2-13b-chat-hf和Baichuan2-13B-Chat.
模型部署的命令如下:
1 | |
其中,template_baichuan.jinja(对话模板)采用vLLM在github官方网站中的examples文件夹下的同名文件。
使用Gradio来构建页面,主要实现大模型问答功能,Python代码如下:
1 | |
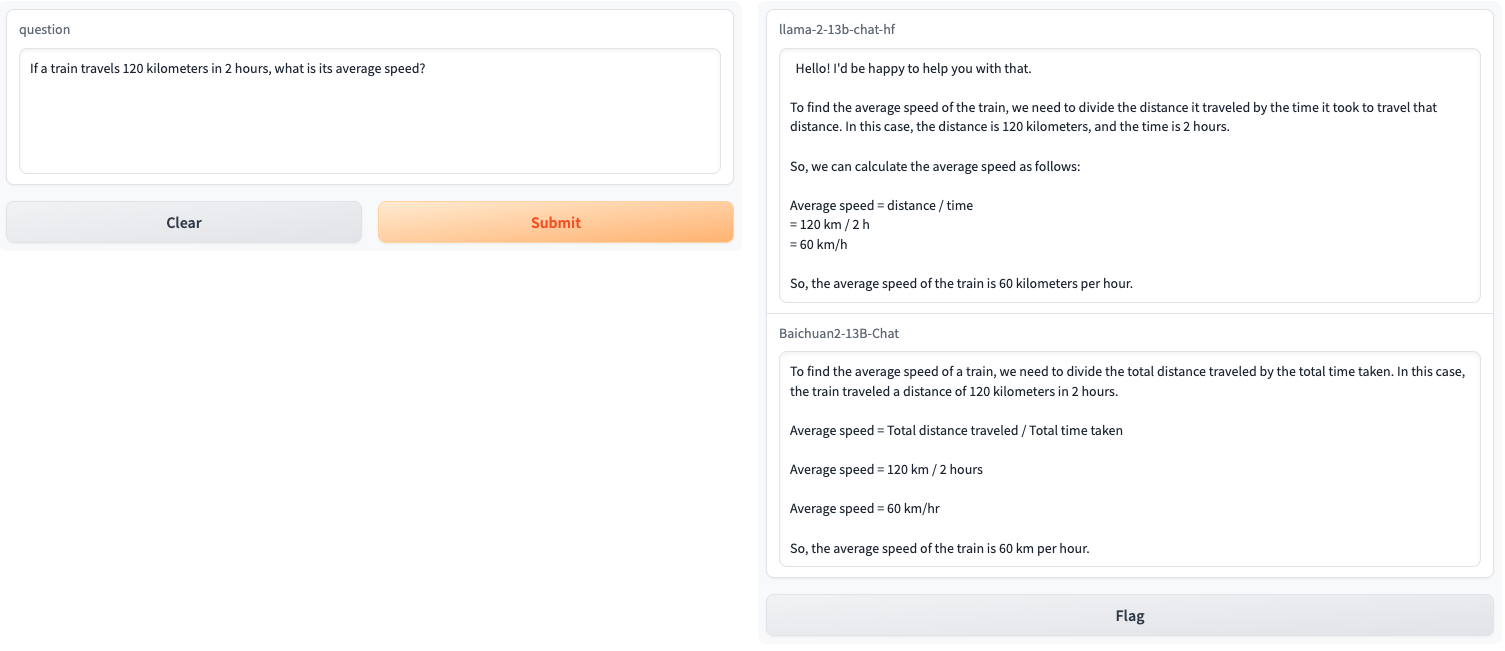
演示例子:
大模型输出TPS
衡量大模型部署工具的指标之一为TPS(Token Per Second),即每秒模型输出的token数量。
我们以llama-2-13b-chat-hf,测试数据集参考网站中的问题集:https://modal.com/docs/examples/vllm_inference
,一共59个问题。
Python代码如下:
1 | |
输出的TPS统计如下:
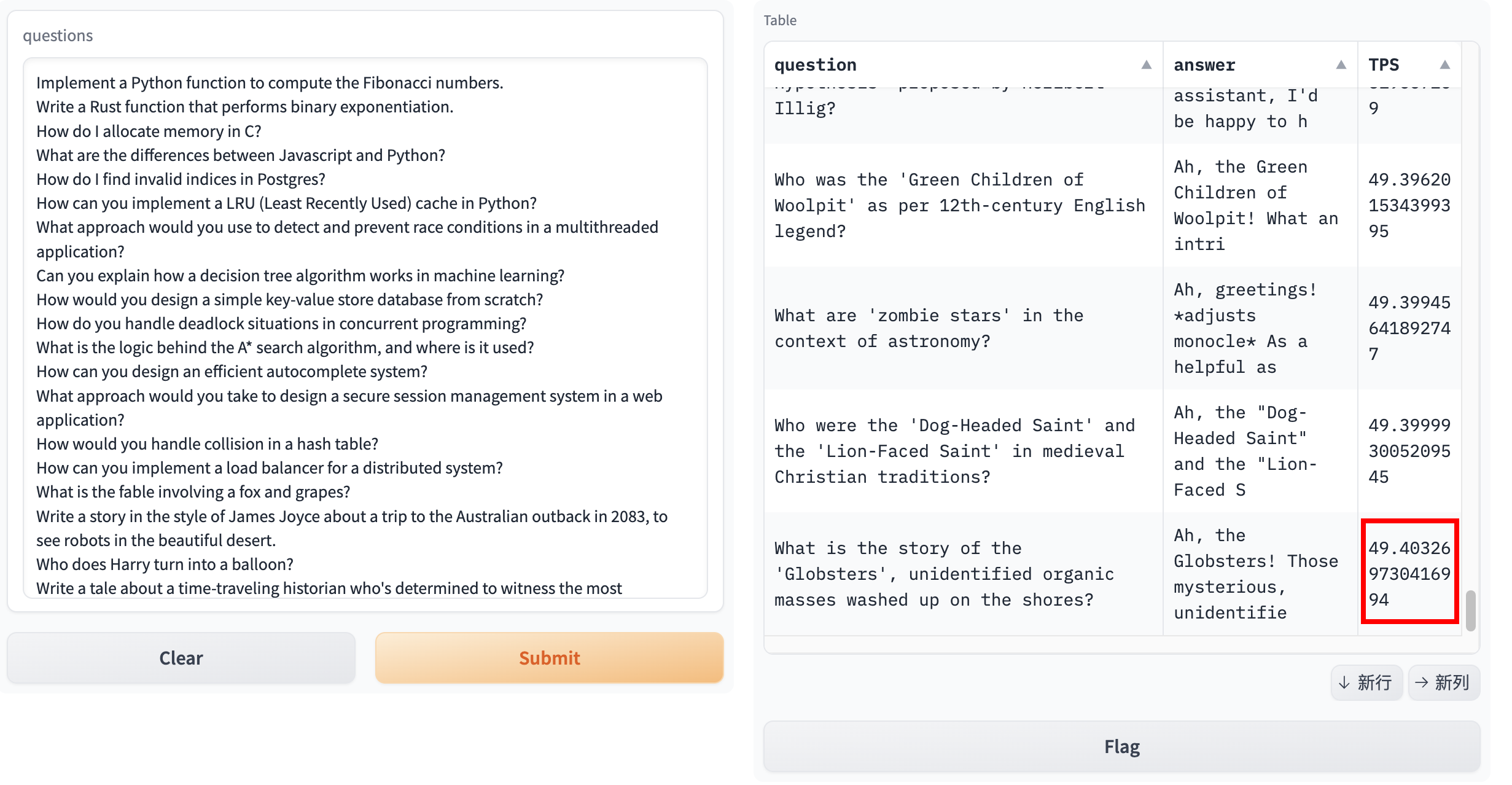
本次实验共耗时约639秒,最终的TPS为49.4。
以上仅是TPS指标的一个演示例子,事实上,vLLM部署LLAMA-2模型的TPS应该远高于这个数值,这与我们使用vLLM的方式有关,比如GPU数量,worker数量,客户端请求方式等,这些都是影响因素,待笔者后续更新。
总结
本文介绍了大模型部署工具vLLM,并给出了其三种不同的部署方式,在文章最后,介绍了笔者对于vLLM的实战。后续,笔者将会对vLLM的推理效率进行深入的实验。
感谢阅读~
参考文献
- vLLM documentation: https://docs.vllm.ai/en/latest/index.html
- VLLM推理流程梳理: https://blog.csdn.net/just_sort/article/details/132115735
- vllm github: https://github.com/vllm-project/vllm
- modal vllm inference: https://modal.com/docs/examples/vllm_inference
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。
